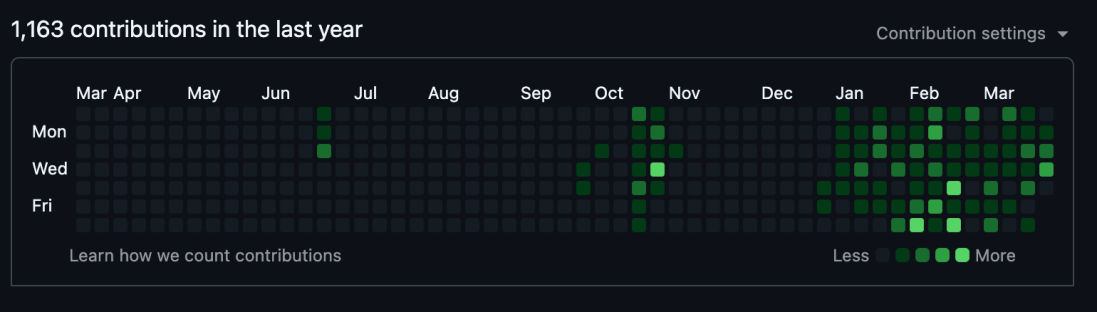
Take a look at this:
Looks amazing, right? Shipping constantly starting from the 1st of January.
Just like from those stories I heard 10 years ago: hey, our 10x guy rewrote the whole thing (front/backend and native apps) because he had a “vision”! How cool is that! Am I finally there?
Reality is of course not that vivid and bright, but overall it is a positive thing.
Here’s what actually happened, what I built, and what I think it means for the future of AI-assisted development.
Is this… AI?

It is.
But on the scale from autocomplete to totally cracked full autonomous multi-agent stuff, it is right in between. See, having a somewhat solid CS degree does make you feel skeptical about AI-assisted development.
Most importantly, this whole AI coding thing was the flipswitch, the “enabler” for me. Knowing how things should be at a higher level of abstraction—thinking architecture (solution)—but being unable to write decent frontend code, this gave me a persistent itch. Combine that with a million and one ideas, and you get frustration.
So it finally started—from small scripts to handle rsync backups and recursively checksum directories (not because you can’t, just don’t want to spend time remembering all the options). Back in the day I would have powered through from scratch, but I already have a more time-consuming hobby: our YouTube channel (more on that later).
From discussing ideas to making scripts, to overseeing projects. This correlates with how models have improved. Better thinking → better code → more autonomy. This is also why I think openclaw’s release came at the right time, if not perfect.
Fast forward, and now there are 3 websites, 2 books in TeX, 1 CLI tool and a Terraform ecosystem.
Before I show what I built, let me address the elephant in the room.
So you just vibecoded it?
Yes and no. But I think there should be a distinction: supervised vs unsupervised vibecoding.
I read all the code written by models and try to understand everything, especially frontend stuff (since I’ve never done it professionally). I never merge without review, and I always try to control the process. But I’m human—I forget things, change my mind, and have limited throughput. I’m the bottleneck here. “We’re not there yet” for fully autonomous coding.
Since I use these tools daily, I treat them as production-level. With 2 other users besides myself, we have a grand total of 3 MAU, so we can tolerate some breaking changes. Obviously this would change if more people start using what I build. But I don’t think the professional skepticism will go away.
My biggest concern is best described here:

Iterating faster didn’t necessarily mean shipping more. In fact, as the codebase grows, I notice quality decreasing (lines written vs lines that actually get merged). Or maybe I just discovered Claude Code’s /review command and this is my new token-hungry hobby.
The problem is, there feels to be no terminal state. No matter what you do, it’s never enough—not even a small README change is safe. This is inherent to coding itself, though the feeling intensifies every time you see “Approved, but with minor changes.”
Maybe I’m doing it wrong. Maybe I need a magical prompt. Maybe another $20/mo subscription to review my code better. Maybe $200/mo Claude Max for multi-agent Opus-at-scale enterprise workflow. Maybe then I’ll finally see code that makes everyone happy. But first—gotta ship a new patch.
Why so many commits?
This rapid iteration comes with its own patterns. I’d say 80% of commits are about correcting bad decisions—no one wants an app that changes completely overnight. And this iteration at the speed of thought lets me learn things and polish the foundation before release—all solo.
I’ve noticed that, like humans, models have different personalities. Some yap more than others, which shows up as going back and forth around the same code lines and writing unnecessarily long comments. Removing and re-adding the same code made squash my default merge policy.
At the same time, we’re blessed with diversity of choice. It still surprises me that my favorite coding model is Minimax M2.5—because it doesn’t yap excessively. Straight to the point, surgically removing issues from the codebase. This feels like an individual trait rather than something controllable from user input. Yappy models also seem to yap during reviews, so there might be room for optimization in model selection.
This exploration of process raises a bigger question: what did all this iteration actually produce?
So what did you build?
Let me highlight three projects: a CLI tool, a web-based analytics tool, and a book.
Yet another YouTube CLI, because why not
My biggest inspiration is wanting to optimize repetitive tasks. For me, that was channel management: analytics tracking, A/B tests with CTR, downloading CSVs in ZIPs and trying to figure out what each contains. Even simple things like “brainstorm titles based on past videos” with LLMs required maintaining data lists.
No MCP (Model Context Protocol) tool solved this. I tried those shady “give me all your keys and use our remote MCP” services on YOLO vibes. If they’d worked, I would’ve kept using them.
So I built the awscli equivalent for YouTube: atomic operations, minimal abstraction, zero knowledge required of how YouTube API works (there are actually two). I only abstracted things like JSON/CSV conversion and pagination—the boring stuff nobody wants to deal with.
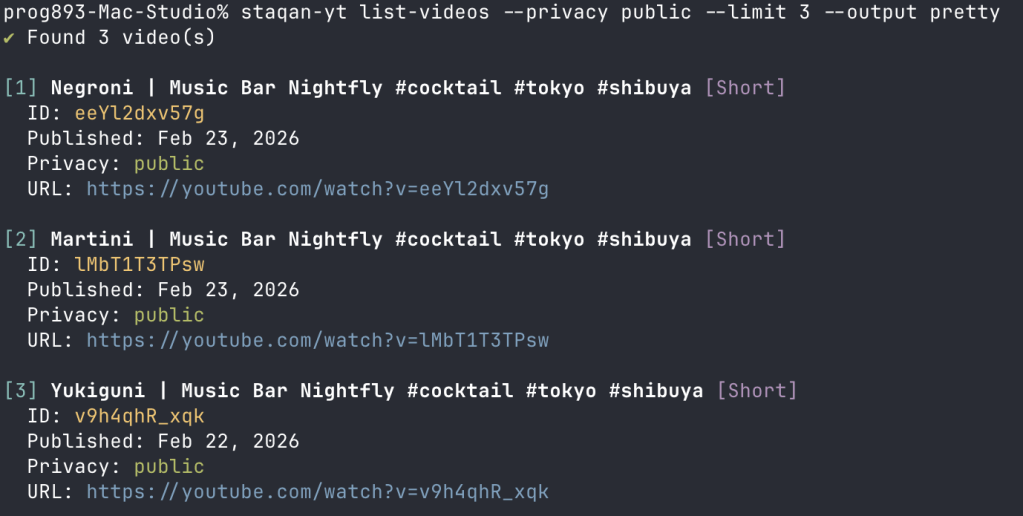
I started this inspired by Bun’s single-file executables, which looked super promising for CLI tools (apparently Claude Code uses this too). In days I had atomic operations working, with a Homebrew formula that compiles to a single binary—no more node version management. What a dream.
This was also around the time MCP token inflation became a thing. I initially built an MCP mode for LLM automation, but the token overhead made me pivot back to CLI as the primary interface. This makes sense: training data arguably has more CLI tool usage than MCP usage. Plus, CLI doesn’t eat context with tool definitions on every session.
The most annoying part was the Reporting API, which has a sliding window of data availability—detailed CTR data gets erased unless you download it. You must “request” a report and wait 48 hours before data becomes available. This naturally led to commands designed for cron jobs: daily fetches and backups to safe storage.
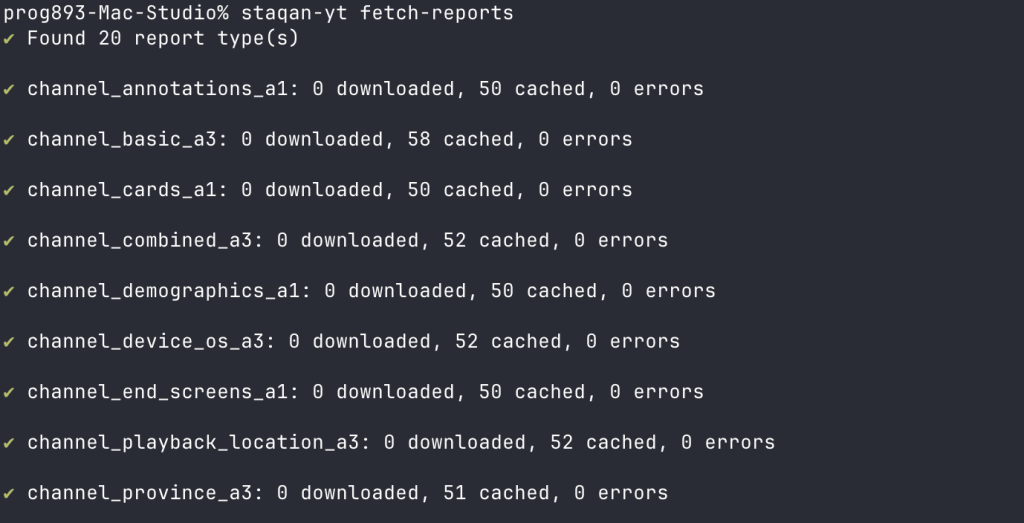
Three months in, it’s working like a fine Swiss wristwatch. zsh completion, jobs, cache, write locks—all the fancy stuff.
Yet another YouTube Studio alternative, because why not indeed
Being a growing YouTuber, you start looking for tools to accelerate growth and make sense of data, since YT Studio is confusing (especially at first). I tested vidIQ, TubeBuddy, and others—they never gave real insights. vidIQ and TubeBuddy are still useful for preparing videos, but we needed something more. And ideally, a web interface for team members who aren’t comfortable with terminals.
And then, a backend engineer discovers shadcn/ui.
See, all the UIs I’d created before—for course assignments or internal tools—were what you see in “HTML for Dummies.” Pure HTML elements, a touch of CSS, zero design understanding. I knew it wasn’t my thing, so I didn’t bother. Things like TanStack, shadcn/ui, even Tailwind CSS were from a parallel universe I’d never heard of. My last attempts to make things look nice were with jQuery and Bootstrap… and now I feel old.
I heard of shadcn/ui from their MCP server announcement. Realizing what a blessing it was (especially for people like myself), I knew I had to build something.
So here it is: whatever YouTube Studio didn’t give me and I had to crunch numbers for myself. The growth dashboard shows all videos aligned by upload date on a time axis. How’s our first 48 hours performing? Are videos growing long-term? Now I have answers.
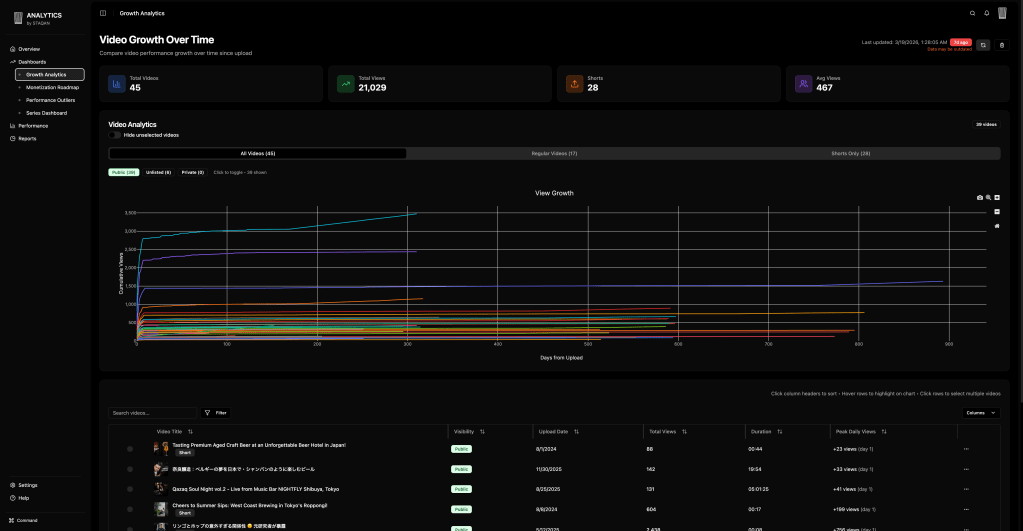
To keep things simple and avoid managing infrastructure on weekends, I went all static and client-side. All data fetching and aggregation happens in-browser, so I don’t worry much about security or GDPR. This means not all things are possible (hello Reporting API), but we work with what we have.
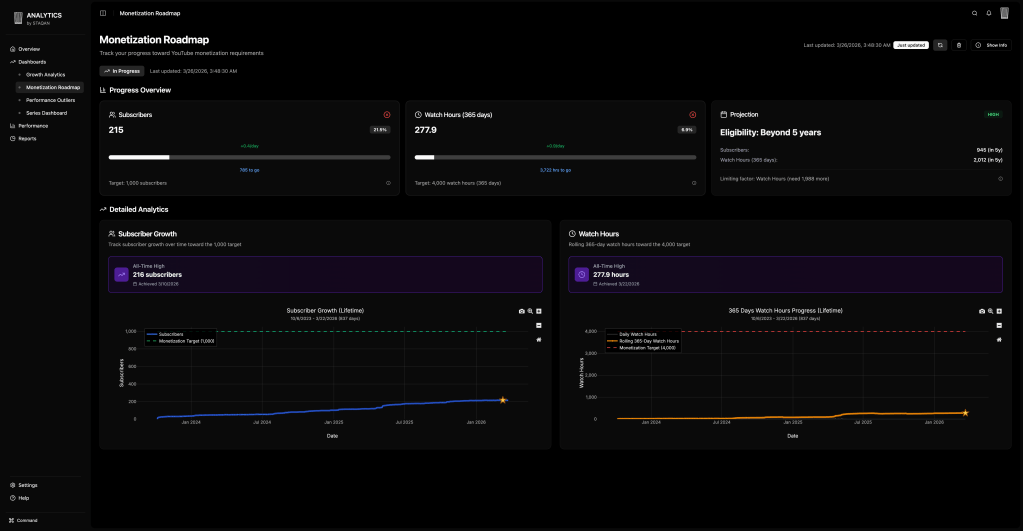
This is still in private beta for friends, but if you’re interested—hit me up on Twitter @prog893, DMs open.
One thing that helped: using TypeScript everywhere. With LSP integration in Claude Code and pre-commit type checks and linters, bugs get caught before commit. Fewer “write broken code, fix it later” cycles. And since everything—CLI tool, analytics dashboard—is in TypeScript, models can cross-reference and learn from patterns across projects. LLMs being genuinely good at writing TypeScript contributed to development speed too.
A couple of books
I fed visual references to a VLM which generated custom TeX style files, leveraging open-source packages and existing .sty files as context. The model could even debug TeX issues. I had a 140-page book in 3 weeks. Based on 5 years of notes, of course. Still impressive, and hopefully life-changing. Coming soon.
So what happens next?
My longer-term predictions:
- It will become much harder to get funded for B2B SaaS. The “if you need it, build it yourself” age is coming, and before that, markets will be oversaturated with variants of the same thing.
- As with AI-generated art and music, taste will remain a relevant “human” skill. Humans will stay bottlenecks—but that’s not a bad thing.
- Solid basic knowledge will be more important than ever. Not just for detecting hallucinations, but for using inference efficiently by steering away from known bad decisions.
My place in this AI world
On a personal level, I’ll continue limiting AI in my creative work. I use it for file management, transcripts, and classical AI tasks like masking and upscaling. We tried web research and fact-checking automation, but hallucinations caused more burns than gains, so I limited usage there.
This isn’t to say “all AI art has no soul” or that there aren’t legitimate force-multiplying tools for artists. Rather: AI wasn’t the silver bullet that every model release feels like (especially with social media hype). We haven’t found tools that fit our budget—or justify paying for instead of humans.
Am I a worse engineer for delegating coding to AI? Delegation is a virtue. I’m creating what I couldn’t before, and I haven’t lost earlier skills. If anything, I feel like a 0.8x engineer became 1x in pure skill, and with AI assistance, 1x becomes 2x. I can now talk about how VITE+ is amazing, or how I eliminated backend needs using pagefind for search. These 3 months have been great exercise—both rapidly building and maintaining things, not abandoning them.
Future looks bright. AI remains a force multiplier for me, maybe even more so. Throwing tasks at AI from laziness is different from using it safely while understanding limitations. Being responsible for what you create. Reminding myself of this is one reason I wrote this.
Unless, of course, something big happens again—which history shows it will—and our paradigm shifts yet again, and the singularity arrives. We’ll have different problems then. But as we wait for whatever future comes, here I stand: a 1x engineer wielding AI’s power, looking at my GitHub grass field, breathing in the fresh spring air. Standing there, observing how much I think I’ve achieved. Like the 10x engineers I once aimed to become.
