「10xエンジニア」って言葉、聞いたことがあるか?一人で十人分の仕事をこなし、時に人の十倍の迷惑を周りにかける敏腕人材を指す言葉として、英語圏インターネッツで昔から使われている。いまだに、「すごい技術者の人材像」としてジュニアレベルの人からは憧れられ、シニアからはミームにされたり。
それで、この画像をご覧に入れよう:
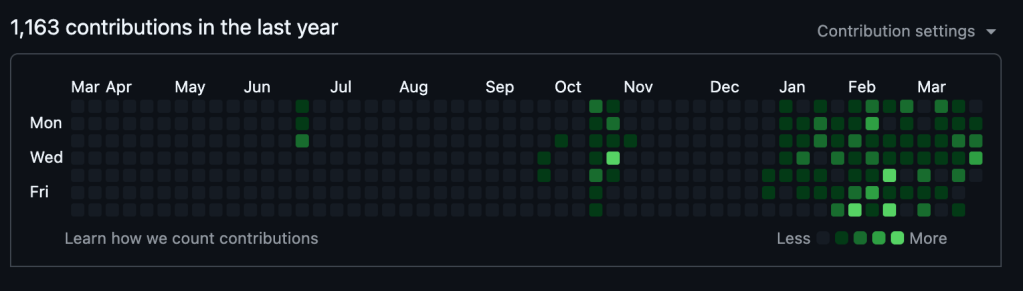
なんかすごそうでしょ?新年早々、一月一日からほぼ毎日、草をはやしてますねこの人。かっこいい!まるで、「その」凄腕みたいに。
IT屋として駆け出しの頃の10年前に聞いた神話を思い出す。「あの凄腕エンジニアが、天啓が降りたかのよう、フロントエンドもバックエンドもネイティブアプリも全部一晩で一人で書き直しぞ!」と。これはいいことなのかは読者に任せる。見方によってはその両方だったりもする。
この草の生やし様を眺めながら、「自分もやっとその域に達したのか」と錯覚を覚えてしまう。言い切ろう、これは錯覚だ。
あまりいいことではないのと同時に、その中にもポジティブな側面もあるのだ。
この数ヶ月に何があったか、何を作ったのか、そしてAI開発の今後はどうなると思うのか、順を追って説明しよう。
「これはAIですか?」

そうだ、AIだ。
「入力補完」から「完全自律型マルチエージェント」までの物差しがあれば、今の私の状態はど真ん中。ある程度ちゃんとしたコンピューターサイエンスの学位を持ってると、こういうものに対して自然と懐疑的になるのは当然だ。
真っ先にはっきり言いたいのは、生成AIが様々なものづくりプロジェクトの「きっかけ」になっている。職業柄、物事が抽象的にどうあるべきか、どう設計され、どう動いているべきかという、プロブレムに対するソリューションを持つアーキテクトとしては、「あれこれ作りたいけど特にフロントエンド書けないからやっぱいいや…」と諦めつつも、ずっとむず痒い。百と十数のアイデアを持ちつつもそれを形にできないという気持ちを抱えていた。
恐る恐る、簡単なものから始めてみることにした。まずは簡単なシェルスクリプトから。ファイルバックアップ用のrsyncラッパーとか、再帰的にファイルの整合性をハッシュしながらチェックしてくれるものとか。だって、コマンドのパラメータいちいち覚えていられないし。再帰的にファイルを処理する時になんでfindとxargsの組み合わせじゃダメだったかも。もちろん、休日に鈍りまくった腕を磨く練習として、古き良き時代のように、補助輪なしで、マニュアルをじっくり読みながら、「正しく」ものづくりするべきだという意見も理解できる。尊重もする。ただ、私にはもう、大量のお金と時間がかかる趣味がすでにもう一つあるからこうはしなかった(駆け出しYouTuberになったんだ)。
世の中にすでに大量あるであろう「ほげふがCLI」を我流で作ろう、みたいな馬鹿げたことについて議論することから、まずはそれなりに動作するものを作る段階へ。やがて複数のプロジェクトを同時に指揮する状態まで進化。より良い推論はより良いコードを生み出し、またより良いコードが書けるならばもっと自律的に動く自由が与えられる。これは人間でもAIでも一緒。そしてopenclawがこの時期に登場した理由でもあるだろう。
気がつけば、3つのウェブサイト、TeXで書いた薄めな本が2冊、CLIツール1つと、やっぱり嫌いになれなかったTerraformのレポ。
具体的に何を作ったのかを見せる前に、一つの大きな疑問に答えなければならない。
バイブコーディングしただけじゃん!
本来の意味でのバイブコーディングは、コード自体をブラックボックスとして扱え、その動作結果のみで出来を計るものと記憶している。そしてその本来の意味よりだいぶ拡大解釈されていることも観測している。教師あり・なし学習の様に、監視あり・なしバイブコーディングに再分類されるべきだと。個人的に思う。なので、この問に対してイェスともノーとも答えることができる。
私のスタイルは「監視あり」側。できる限りAIが書いた(あるいは生成した、というべきか)コードをなるべく全て読み、理解した上で対話するようにしている。特に、経験の浅いフロントエンド周りのコードは勉強になるところが多い。見もせずにマージするようなことは絶対にしないし、プロセスは常に自分でコントロールするようにしている。まぁ人間なので物事を忘れたり、気分が変わったりすることもある。また、AIモデルより認知スループットが限られている存在として、このワークフローにおける最大のボトルネックもまた、私だ。感覚的に、我々はまだ「人間の監視なしでAIに任せられる」状態からは技術的に遠いと感じている。
「作るモノ」は自分自身が使うものとして、それなりの「本番クォリティ」を担保する努力はしている。他にフィードバックを提供してくれている友人2人を入れたら、MAUはなんと3人!なので、多少の破壊的変更は致命的ではないから、スピードが明らかな犠牲になる意思決定はそうは多くない。もちろん、ユーザー数が(願わくば)3人を超えたら、この開発フローを見直さなければならなくなる。ただ、ある程度の専門技術者として持つ様々な懸念が晴れず、基本姿勢が大きく変わることがないと断言したくなる。
その懸念は、この画像を見ればわかってもらえるはず:

「脳を加速させる話題の新薬を飲んだんだ。」「じゃあ頭良くなったの?」「バカが加速した。」
より速くサイクルを回せるようになったからと言って、必ずしもより多くの機能を実際にリリースできるようになったとは思えない。むしろ、コードベースが大きくなるにつれて、質が下がっているように感じる。具体的には、(モデルが)書いた行数に対して、実際にマージされる行数の比率が下がっていると言えるだろう。もしかしたら、Claude Codeに最近追加された/reviewコマンドを使いすぎているだけかもしれない。理由はどうであれ、何らかの変更を加える作業自体が終了状態を持たないものとして認知され、終わりが見えない。もちろんその性質においてコーディングというものは終了状態を持たない(つまり、なんの修正を求めない完璧な状態がない)。ただ、AIによるレビューを回すたびに現れる「マイナーチェンジの提案があるけどマージしてヨシ!」という言葉が、何回言われても耐えることなく、またそれを読むたびに「終了状態のなさ」をより強く感じる。
やり方が間違っているかもしれない。万事解決してくれる魔法のようなプロンプトを持っていないだけかもしれない。あるいは、もっと良いレビューを出してくれるツールのためにさらに月20ドルのサブスクを契約すべきなのかもしれない。もしくは、月200ドルのClaude Maxにアップグレードして、マルチエージェントで複数のOpusに理論上ベストなコードを生み出すエンタープライズワークフローを組むべきか。そうすればきっと、ようやく、AI自身が満足いくコードを、AIが書けるようになる。その前に、先にあのパッチをリリースしなくては…
なんでコミットが多いの?
「より速く試行錯誤できる」状況が原因。高速にプロトタイピングするには、書いては消し、作っては壊す過程が必要だ。感覚的にコミットの80%程度が、過去の誤った判断を正すためのものになっている。一晩で完全に別物になったアプリケーションなんて誰も使いたくないはず。それと同時に、この高速な構築と再構築の繰り返しのおかげで、多くのことを学び、そして長く保持できる最適な基盤を築くこともできる。たった一人で。
人間同様、AIモデルにも個性があって、その個性が効率を左右する。おしゃべりが好きなモデルほどそのおしゃべりと余分なコード(そしてコードの中の過剰なコメント)を生成する、というのはその一例だ。この余分なコードを書くという点が、前に書いたコードを書き換える、前に削除したものをまた戻す、という動作にもっとも強く現れ、これが原因でマージのポリシーをsquashにしている。
同時に、我々が多様なモデルがあることに恵まれている。今だに驚いているのが、執筆時点でのお気に入りコーディングモデルがMinimax M2.5で、そしてそれが「余分におしゃべりしないから」であること。的確に問題を摘出する、まるでコードの外科医のようだ。一方で、おしゃべりなモデルはレビュー時にも、時に必要以上におしゃべりする。この観点で、コーディングとレビューでモデルの使い分けと選定を見直すことによる最適化の余地がありそう。
では、このようなプロセスを経てどのようなものが作られたのか。
で、何を作ってるってんだい?
CLIツール、Webベースの分析ツール、そして本の執筆を例として紹介しよう。
YouTube チャンネルをCLIからいい感じに管理できるヤツ
もっともモチベーションが高まるのは、削減できるムダを見つけた時。技術の力で物事を最適化あるいは自動化して、リソース不足を解消できたら気持ちいい。ということで、ここしばらく土日を持って行かれているのは、YouTubeチャンネルの管理業務。アナリティクスを眺めたり、A/BテストがCTRに及ぼす影響を確認したり。ダウンロードしたZIPで固められた変な名前のCSVには何が入ってるんだっけ…と頭を傾げたり。新しい動画をアップロードするときに「過去に上げてきたものを参考にタイトルのアドバイスを頂戴」とLLMに聞いても、そのコンテキスト自体を揃えてあげる業務。
なんかいい感じのMCP (Model Context Protocol)サーバーでできそうなものばかり。ただ、意外なことに、何を試してもうまく動作せず、あるいはremote MCPとして動作する怪しいSaaSに対して(他の選択肢なく)かなりゆるい権限のクレデンシャルを渡しても、どうにもならなかった。
ということで、awscliにインスピレーションを受け、YouTube APIでいうところの「それ」を作るに至った。できるだけ抽象化は避けつつ、実は2つもあるYouTube APIの仕組みを知らなくても使えるようにすることを目的とした。抽象化することにしたのは、JSON/CSV変換やページネーションみたいな誰もが考えたくない、ツールにやってもらいたい部分のみ。
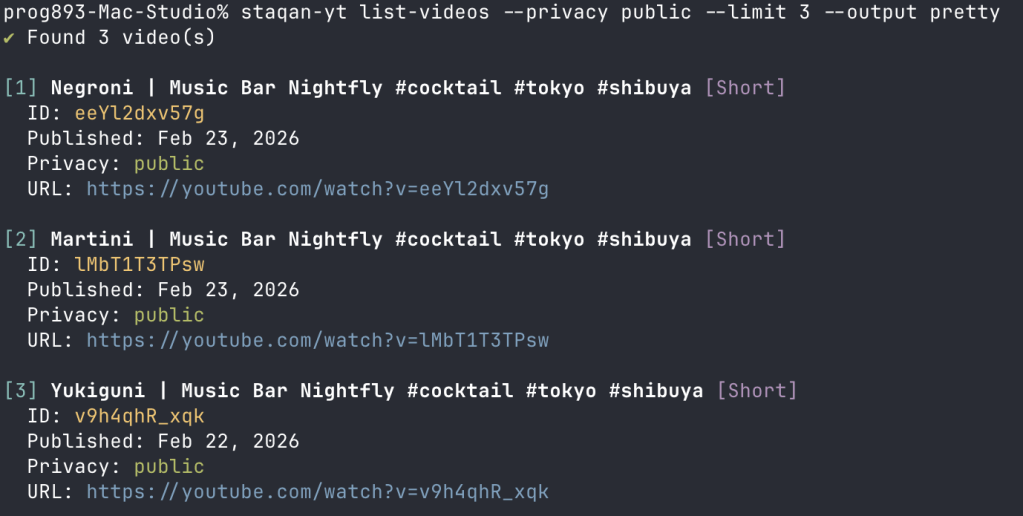
もう一つのきっかけになったのは、Bunのsingle-file executablesを知ったこと。TypeScriptや周りのエコシステムの恩恵を受けつつ、完成品は単体のバイナリにできるものなんてあったら、CLIツールをめっちゃ作りたくなるじゃないか。どうやら、Claude Codeもこの仕組みを使ってるらしい。
数日で、最低限の機能が揃い、Homebrewで配布する周辺スクリプトも整った。Homebrewでインストールした結果も単体のバイナリなので、node自体のバージョン管理からも解放されて、「最高」以外の言葉が見つからない。
後に、LLMを使った自動化のためにMCPモードも追加した。ただ、コンテキスト消費という側面でのオーバーヘッドが大きく、自分自身も、私のエージェントたちも、CLIしかインターフェースとして使わない。確かに、学習データには、MCPよりCLIツールを使った例のほうが多く入っているはずだ。
このツールを作る時にもっとも面倒だったのはReporting API。レポートをまず作成してもらわないといけなくて、できるまでは48時間待ち、できてから新しいデータが毎日追加されるが、古いデータは消えていく。特にCTR周りのデータはこのAPIしか得られないものが多い。次第に、cronに繋げることを前提としたレポート保存コマンドと、保存されたものを安全な場所(クラウドストレージなど)にエクスポートする機能を追加することになった。
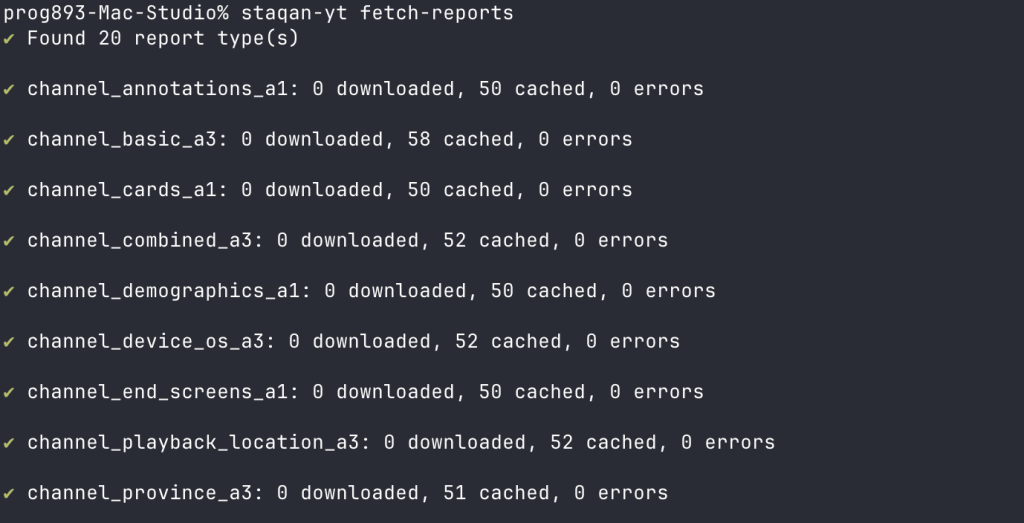
なんだかんだたったの3ヶ月で機能が揃い、安定して動作するものができた。zshの補完、データ書き出しジョブ、キャッシュ、書き込みロック、本番利用で必要になるはずのものを全て揃えた。
そんなツールが、これだけでインストールできるのだぞ
brew tap prog893/tapbrew install staqan-yt
YouTube Studioがいい感じに見せてくれないグラフを見せてくれるヤツ
駆け出しYouTuberとして、どうすれば再生数や登録者数を伸ばせるかが気になる。そしていずれ、その答えを出してくれるツールも求めている。正直、YT Studioは初見ではかなりわかりにくい。私自身もvidIQやTubeBuddyを始めとしたツールを数多く、課金して試してみたが、すでに知っていたものやあまり信頼できない「点数」みたいなもの以外は得られなかった。vidIQとTubeBuddyだけが動画公開前の準備段階で大変お世話になっているから継続して、残りは全て解約した。ただ、やはり公開後の動きや過去のパフォーマンスが、うまくいったものとそうでないものとで比較できるような形で、何かがほしい。わかりやすく、次の動画はどうすればいいのかというアクションがすぐ決まる、そして他のメンバーもすぐ使えるようにWeb上でGUIを持つ何か、だ。
これを作る「時が来た」と感じたのは、shadcn/uiと出会った時だ。
どちらかといえばバックエンドよりのエンジニアとしては、これまで作ってきたものが、大学の講義とかHTML/CSS入門書に出てくる「それ」だけ。必要最低限、動作さえしてくれればいい。できないからしない、というより、デザインセンスもフロントのスキルも持たないし、本職はそっちじゃないから、できないからしない。フロント寄りの皆さんなら誰でもきっと知っているであろう、TanStackもshadcn/uiもTailwind CSSでさえも、知らなかったしTwitterでも流れてこなかった。最後にある程度それっぽいUIを作ってみようとした時には、確かjQueryとBootstrapの時代で…年取ったなぁ…
shadcn/uiを知ったのは、MCPサーバーの発表記事が流れてきた時だった。「これは革命だ、特に俺みたいなデザインが苦手な人間にとって」と確信し、久しぶりにGUIに挑んだ。
そして、求めていたものが完成した。YouTube Studioが教えてくれなかった分析機能のダッシュボード集。全動画をアップロード初日に合わせて時系列で並べるダッシュボードが特にお気に入りで、YouTubeでもっとも大切な「アップロードからの最初の48時間」のパフォーマンスを動画間での比較を可能にする。我ながら素晴らしい。
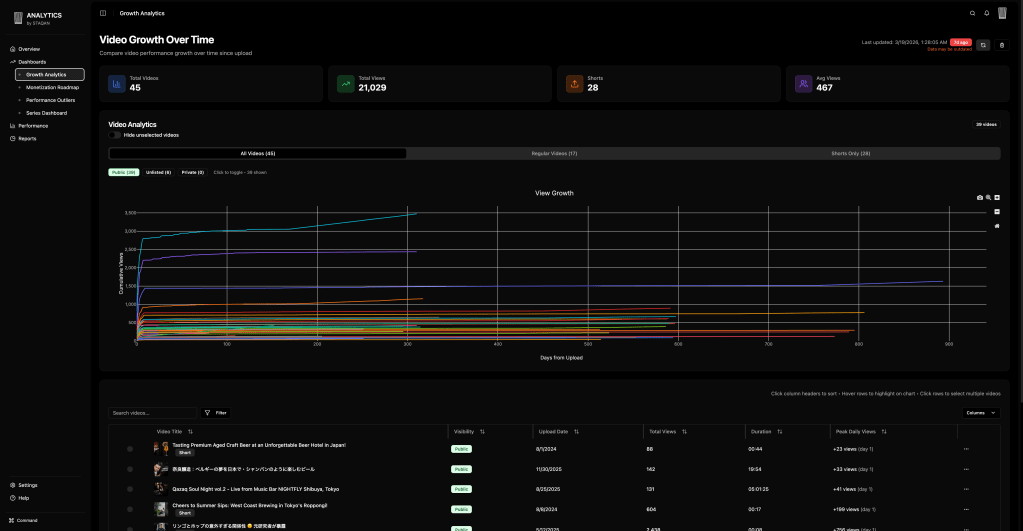
できる限りの作りのシンプルさ、そしてインフラの管理を避けるために、staticページのみ、フロントエンドのみで動作するように設計した。データの取得、キャッシュはブラウザ内でのみ行われるので、セキュリティやGDPRなどのプライバシー問題はあまり考えなくてもよくなる、というメリットもある。同時に、上述のReporting APIという厄介者は扱えなくなるので、今の段階ではこれはまぁ仕方ない。
これはまだ招待制プライベートベータとして公開しているが、興味があればTwitter @prog893 DMまでお問い合わせを(ベータユーザ募集中)。
このプロジェクトでは大いに助けたのは、TypeScriptを採用したことだ。CLIツールもTypeScriptで書かれていたので、そのコードを参照したりパターンを学んだりしながら、分析ダッシュボードが素早く実装できた。また、Claude CodeのLSP統合とpre-commitの型チェックやlinterのおかげで、バグはコミットする前に見つかる。「壊れたコードを書いて、後で直す」というサイクルが減った。そしてそもそも、LLMはTypeScriptを書くのが得意な点も開発スピードに貢献した。
薄めな本、何冊か
見せたくてたまらないのだが、まだ未完成。進め方としては、気に入った本などのビジュアルリファレンスをVLMに与え、カスタムTeXのstyファイルを生成してもらった。オープンソースのパッケージや既存の.styファイルをコンテキストとして活用し、モデルはTeXの問題のデバッグさえできた。3週間で140ページほどの読み物が出来上がった。もちろん中身に関してはAIに書かせたものではなく、5年間を通して残してきたメモのまとめみたいなものなので、大半の時間がTeX自体のデバッグに消費された。いずれにしろ、衝撃的だ。そしてうまくいけば、私の人生の転換点となるものになる可能性を秘めている。乞うご期待。
で、将来はどうなると思う?
いくつかの長期的な予測をここで述べたい:
- B2B SaaSのようなサービスの資金調達は、めちゃくちゃ難しくなる。「必要なものは自分で用意すればいいじゃん」時代がもうすぐ(完全に)訪れる。そして、同様なもので市場が溢れ、飽和状態になる。
- 生成AI「アート」や音楽においてすでにそうなっているように、「センス」は人間のスキルとして残る。人間はボトルネックであり続けるが、これはデメリットとしてみるべきものではない(むしろAIにリプレースされない)。
- しっかりした基礎知識が、これまで以上に重要になる。生成された内容の正確性を評価するためのみならず、明らかに間違った判断を避けるような指示、判断をすることによる推論リソースの効率的な利用のために不可欠なものとあり続ける。
AIの波の中、自分はどこに
「AIと私」みたいな、短期的なAIとの付き合い方の見通しは、やはりクリエイティブワークの核心的なタスクにおいてはできる限り避ける、というスタンスが変わらないと思う。ファイル管理や文字起こしというタスクにおける補助としては、アートの部分には触れない、人間の魂を必要としないタスクは、委託しても問題ないものだと思う。また、マスキングやアップスケーリングなどの、どちらかといえばレガシー寄りなものについては、今まで以上に注意しながら使い続ける。AIに対してタスクの責任をとることになるのはそれを委託した人間となる。以前はウェブ上のデータからのブランドリサーチ、のようなタスクを丸投げして、またそのチェックを何度か任せてきたが、何度もハルシネーションの被害を受けてきた結果としての判断だ。もちろん、「すべての生成AIアートはアートではない、人間の魂が宿っていない」と言うつもりでもなければ、アーティストの制作時間を短縮するAI搭載ツールの中で良いものがない、と言いたいわけでもない。一つ目に言えるのは、AIモデルが出るたびに思う「銀の弾丸」ではないこと(特にSNSでインプ稼ぎをしたり情報商材を販売する人たちを見ると特にその錯覚に陥る)。もう一つは、我々のユースケースにおいて、かつ予算に合ったツールを見つけていないこと。もしくは、これに投資してもいい、と思えるツールに出会えていないだけかもしれない。
本題に戻ろう。自らコードを書かずに、AIにコードを書かせていることが怠惰なのか?これによって自分のスキルが落ちたのか?タスクを委任できることが美徳だと思う。委任するスキル自体が磨かれ、委任することによって自分ではこれまでできなかったことができるようになっている。コードを自ら書かないことによる多少の衰えがあれど、これまで持っていたスキルを大きく失っているとは思えない。また、コーディング自体が手段であり目的ではない。感覚値として、補助なしで0.8xエンジニアがやっと一人前になった感覚があり、そしてAI等のツールによる補助がこれにかかる係数となる。モダンな技術の、例えばVITE+の素晴らしさを使っている身として語れたり、あるいはpagefindを使ってバックエンドなしで検索機能を実装したことを、それを理解した上で紹介できたりするようになっている。そしてこの3ヶ月間は、キャッチアップと模索のためのプロトタイピングと、リアルユーザを抱えるメンテナーとしてプロジェクトの維持と保守のいい練習になっていると思う(そして改めて、その全てを一人で)。
どちらかといえば、未来は明るい。AIは今もスキル値に対する乗数(英語ではよくforce multiplierという)であり続ける。
めんどくさいからAIに丸投げすることと、その技術の制約を理解した上で適切に付き合うことは大きく異なる。人間にしかできないことを理解した上で、ツールを適切に使う。このことを自分自身に改めて言い聞かせること、実はがこの文章を書いた理由の一つ。
もちろん、歴史がこれまで示してきたように、革新的な何かが出てきて、またパラダイムをシフトさせざるをえなくて、シンギュラリティが訪れて…全てがひっくり返る時が来る。そこまできたら、考えるべき問題が、だいぶ変わるだろう。そして今は、私がここに立っている。AIの力を借りたただの1xエンジニアが、春の新鮮な空気を胸いっぱいに吸い込み、GitHubの草原を見渡す。かつて憧れた10xエンジニアたちになれた気分で、未来を眺める。
